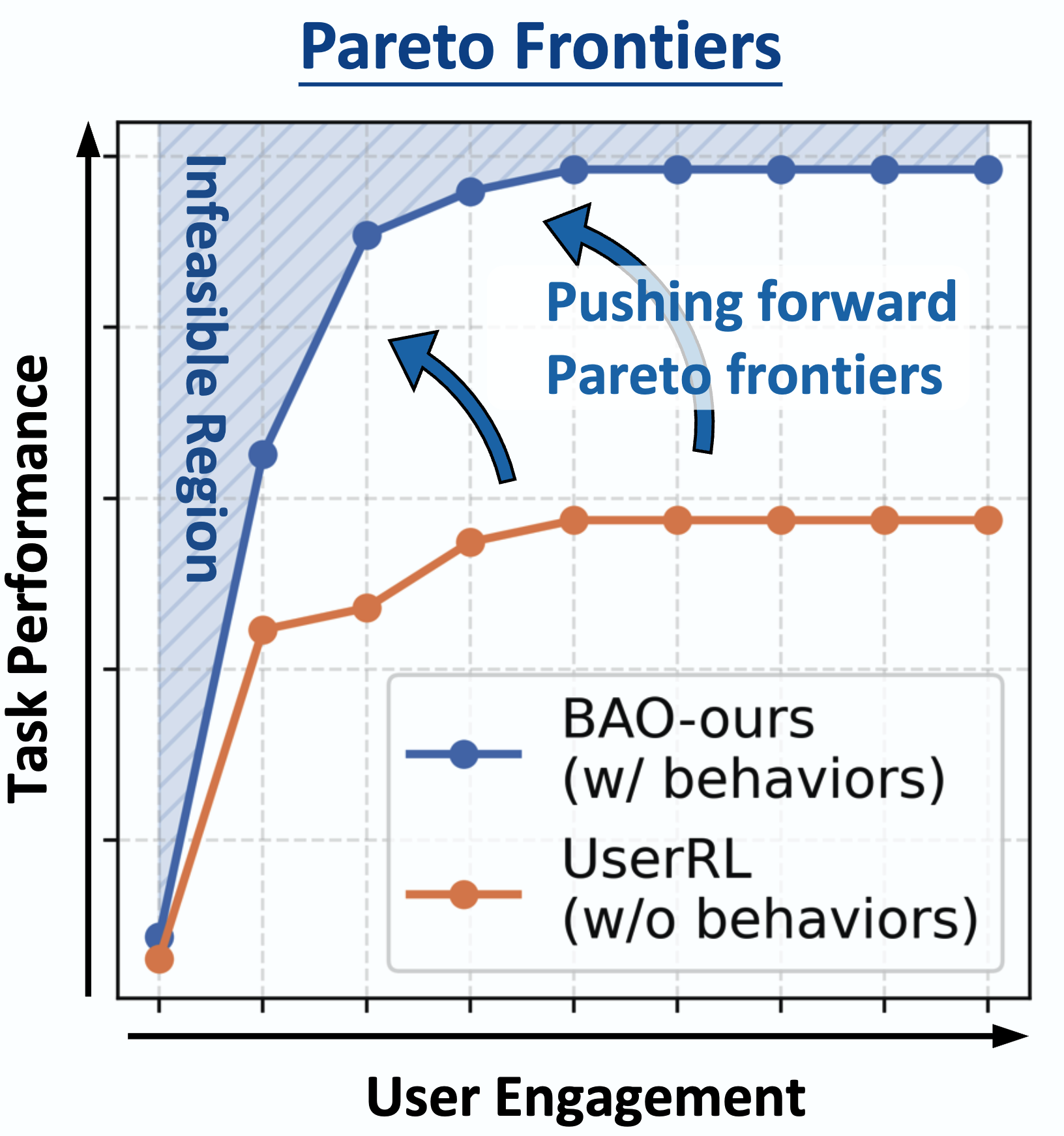
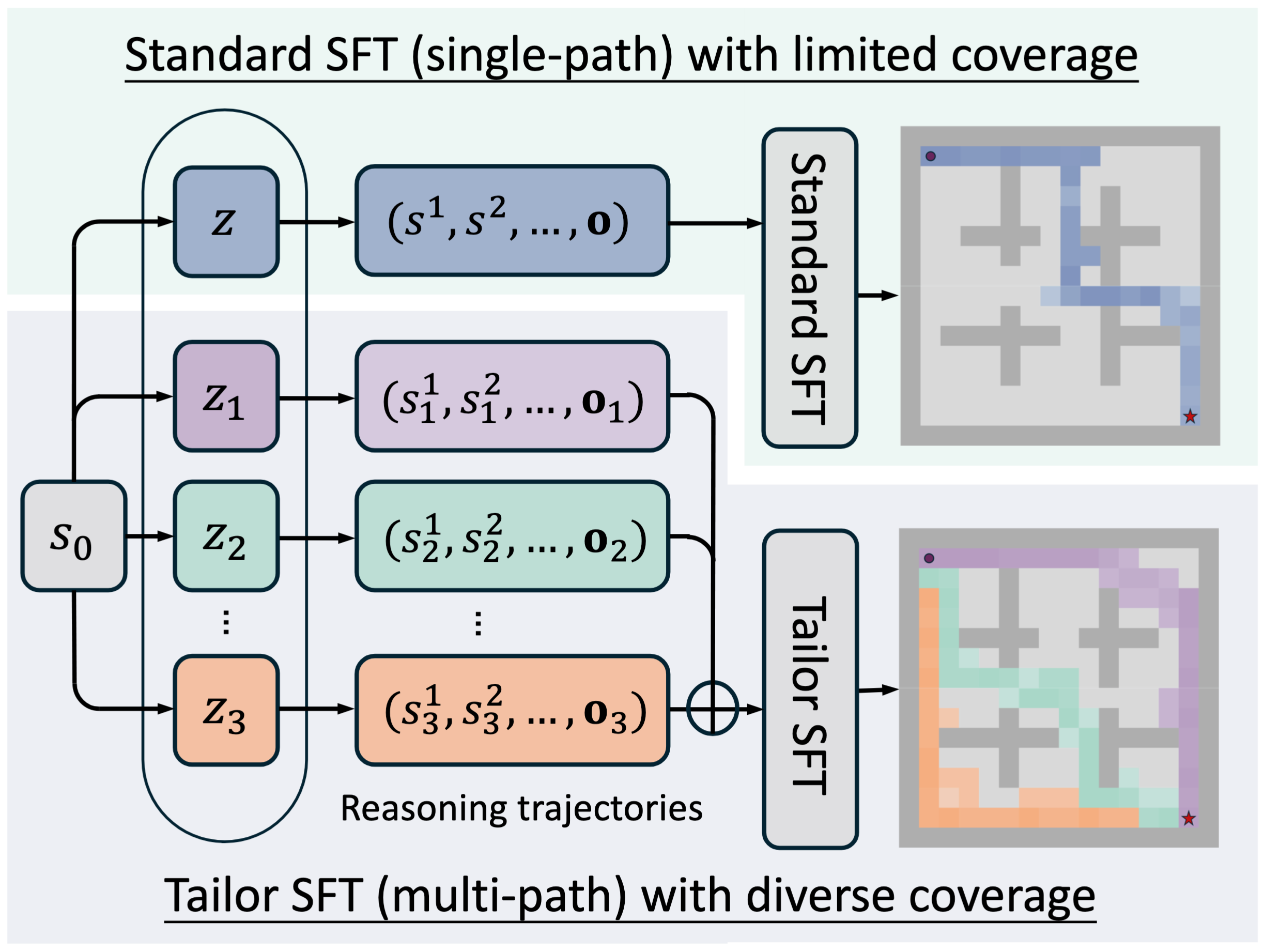
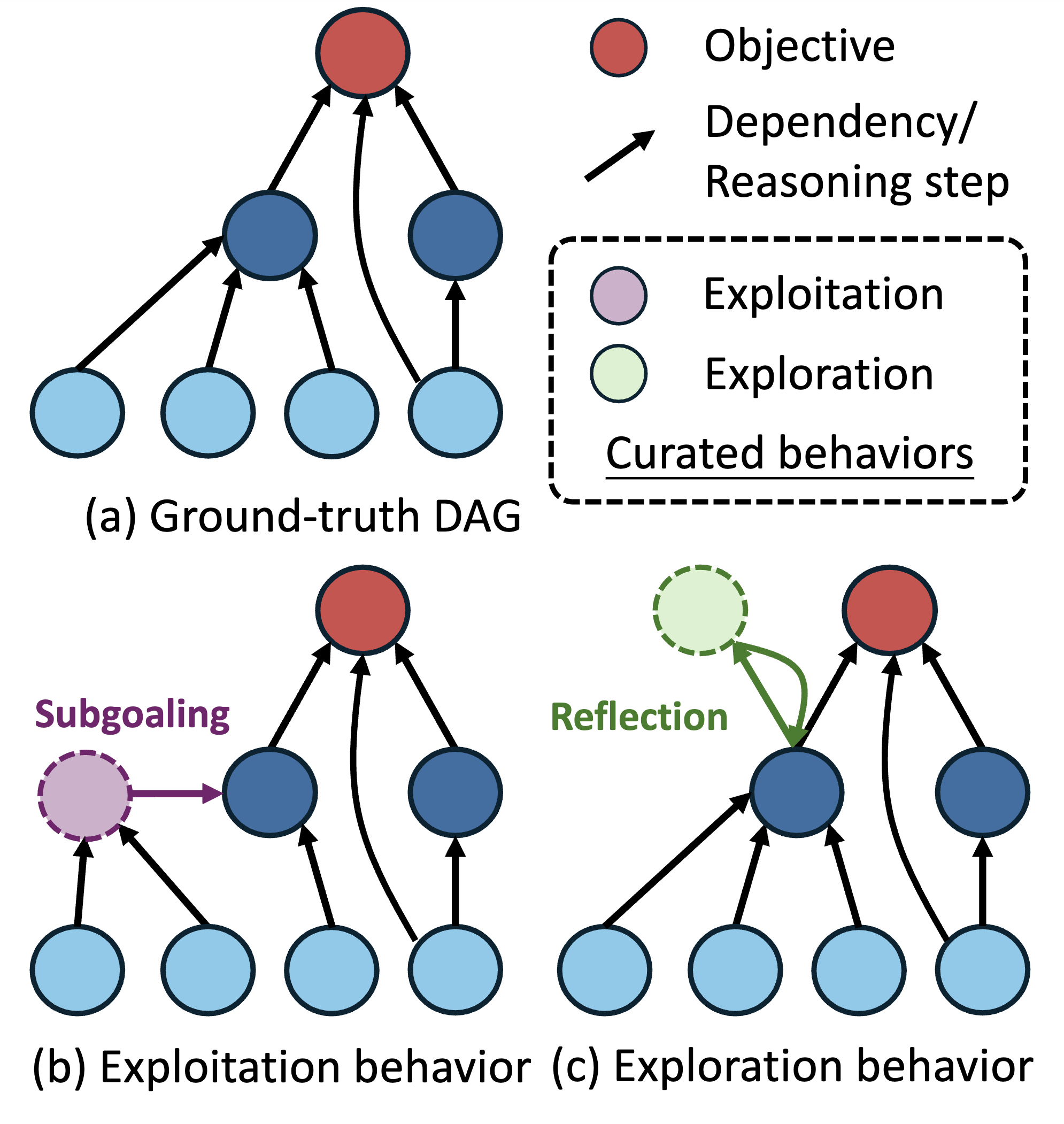
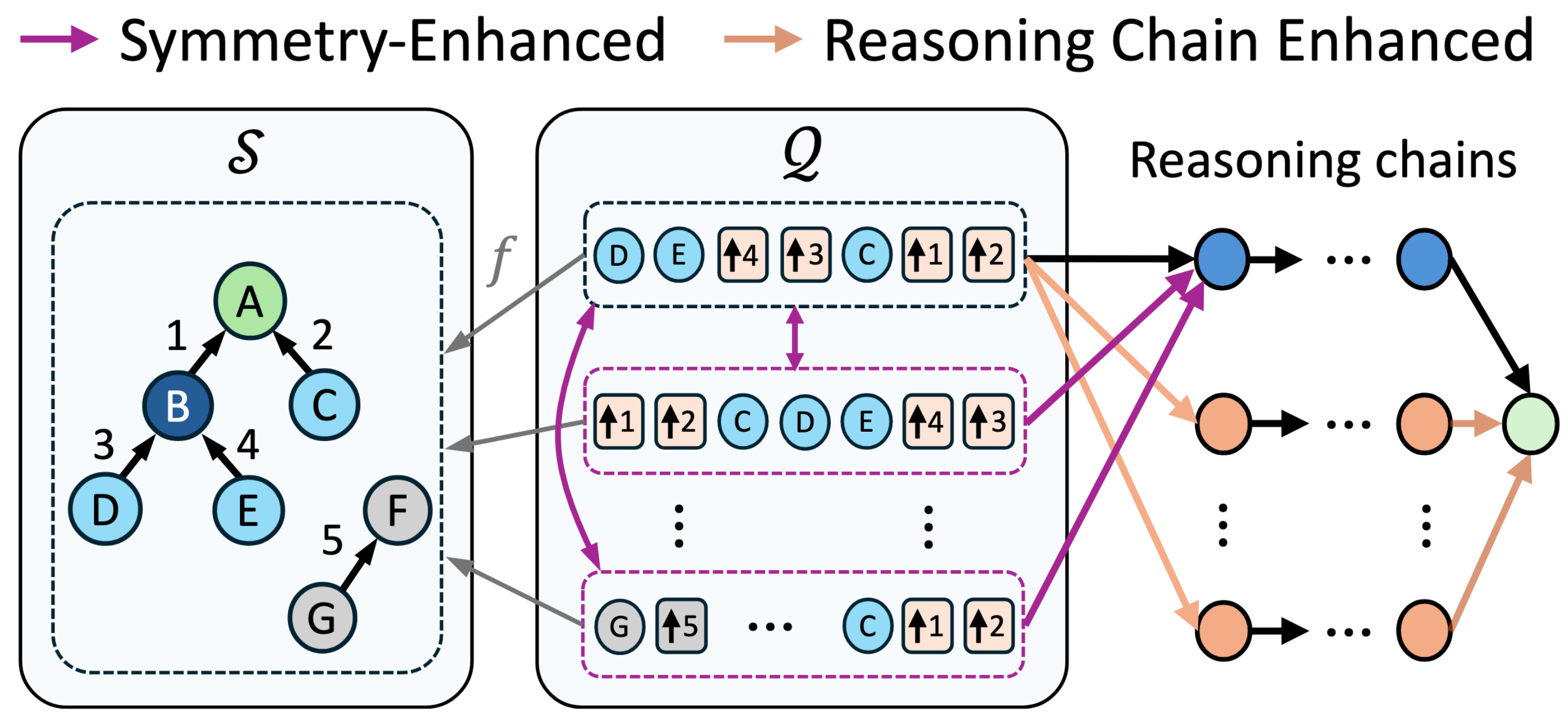
Yihang Yao yihangya[at]andrew.cmu.edu
Hi, welcome to my website! I am a 4th-year Ph.D. candidate in the Safe AI Lab at Carnegie Mellon University, advised by Prof. Ding Zhao. I received my Bachelor's degree from Shanghai Jiao Tong University in 2022 and spent a wonderful time as a visiting student in the Intelligent Control Lab at CMU, working with Prof. Changliu Liu. I previously interned at MIT-IBM Watson AI Lab, IBM Research and have also been working with Google DeepMind since 2023.My research focuses on reinforcement learning and large language models, with a current emphasis on self-evolving agents and environment scaling. My prior research experience also includes:
- Agentic RL for Proactive LLM Agents [ICML 2026]
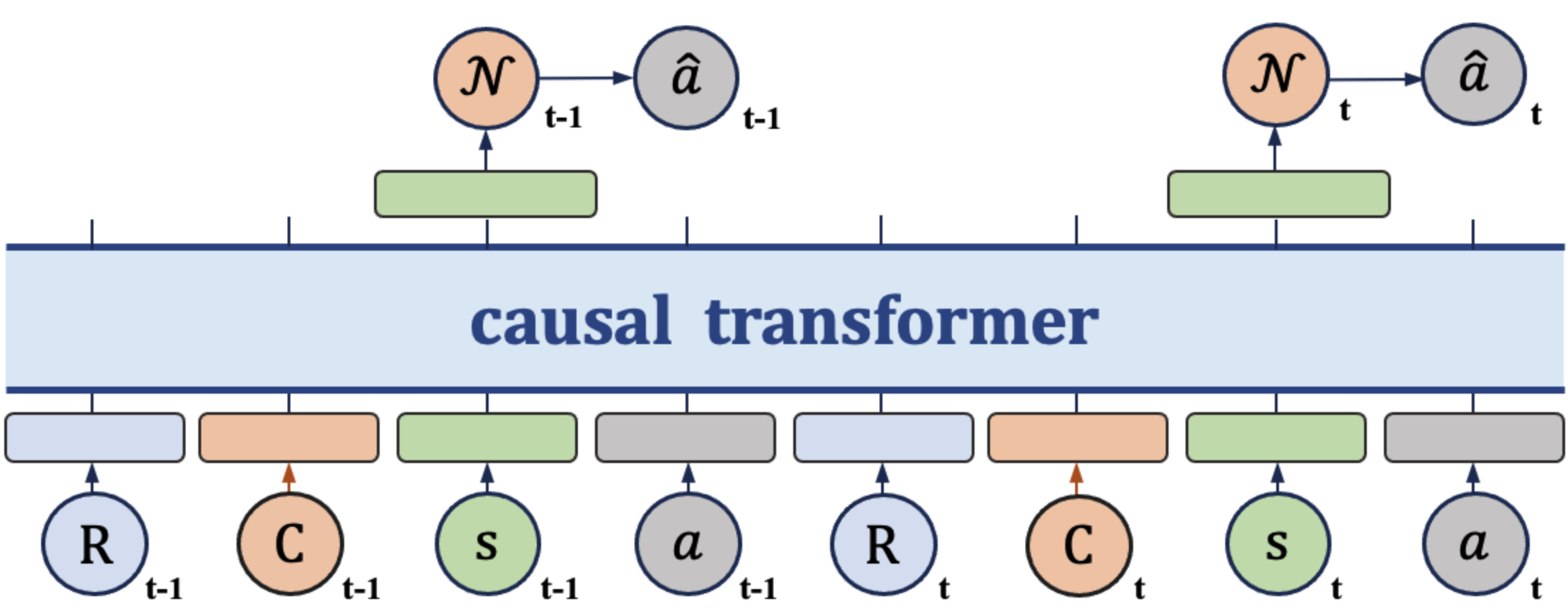
- RL Foundations for LLM Post-Training [ACL 2026, NeurIPS 2025]
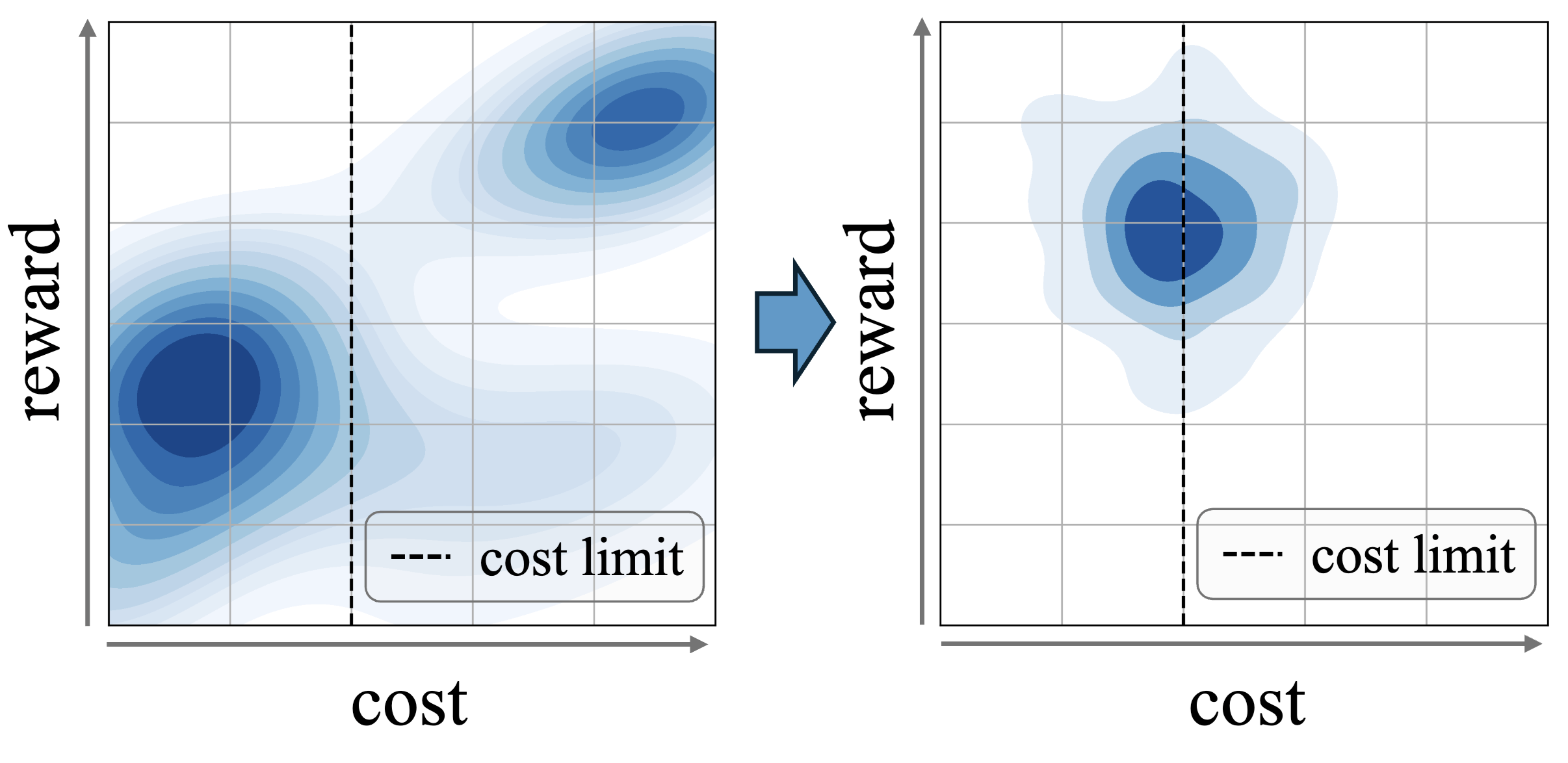
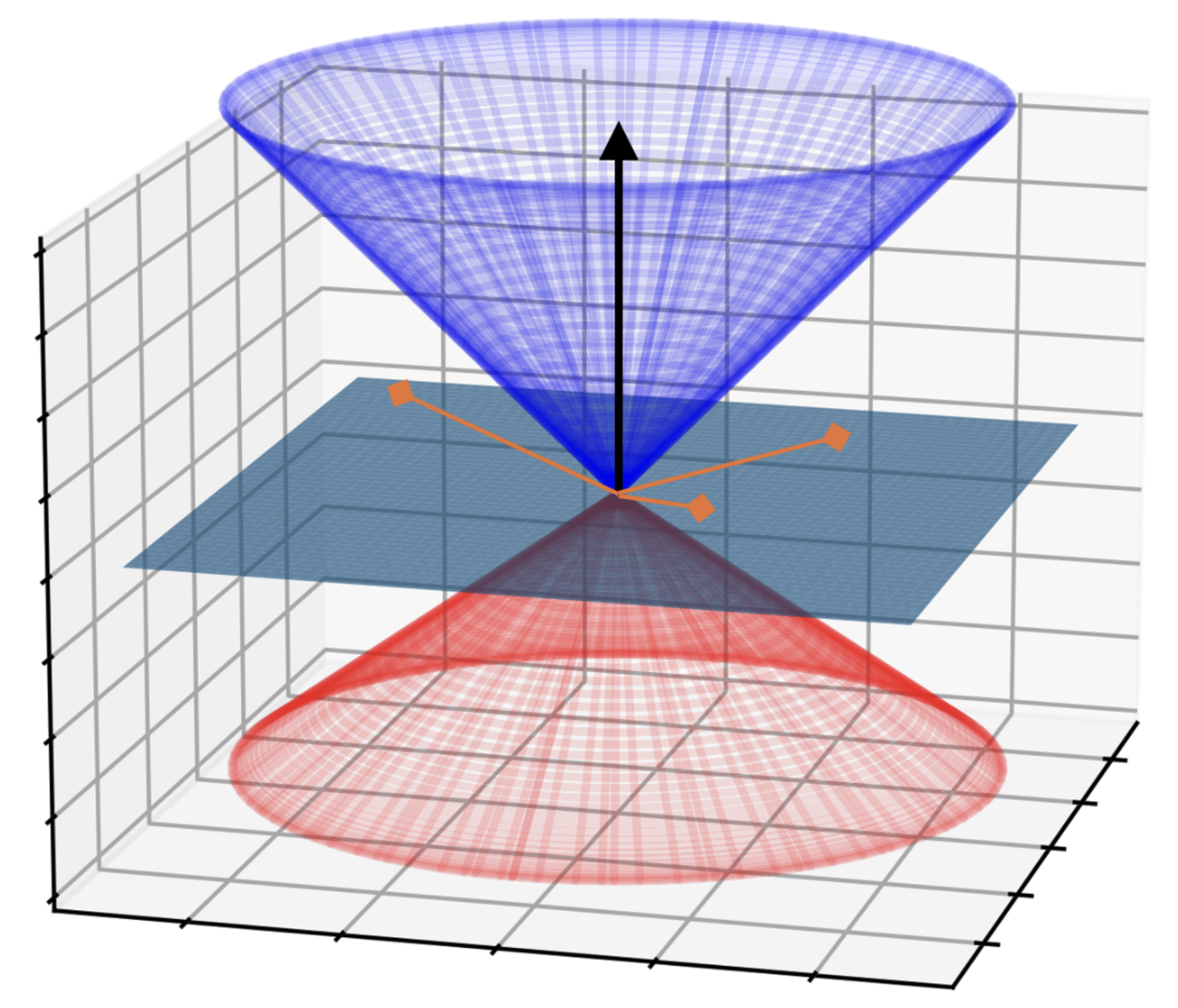
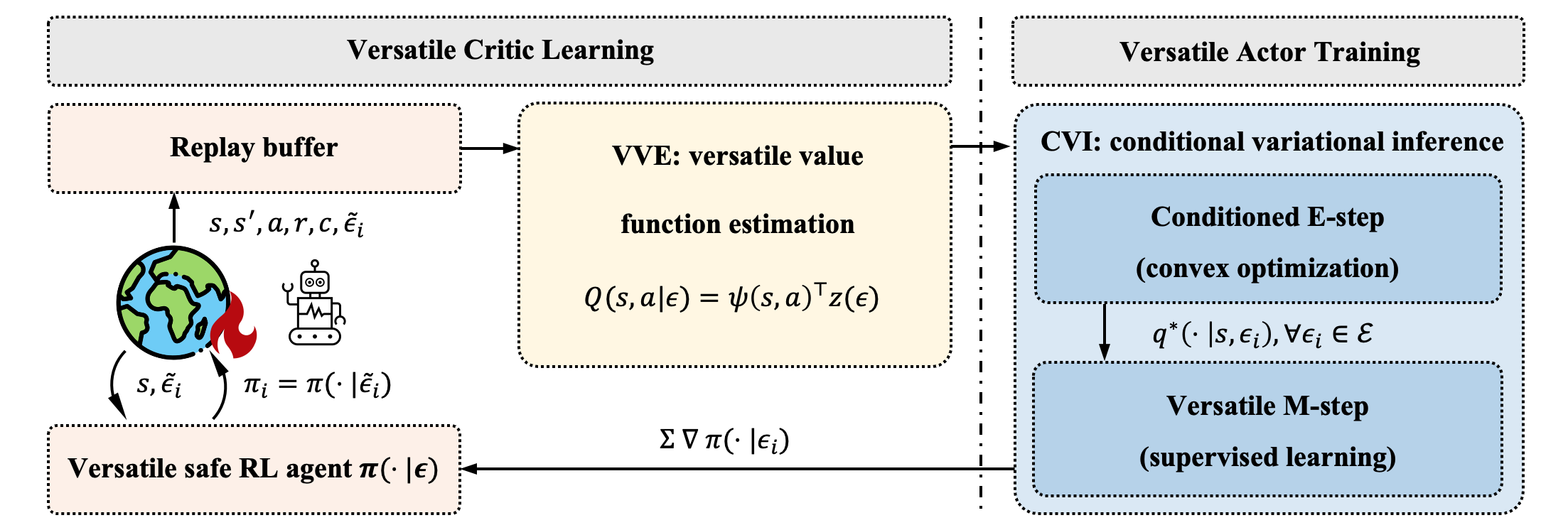
- AI/LLM Safety and Robustness [NeurIPS 2024, NeurIPS 2023, L4DC 2024, ACL 2025]